안녕하세요, 이은재입니다.
Sanity
지난번 에피소드에 Sanity 라는 Headless CMS 에 대한 이야기를 조금 꺼냈었는데요. 바로 이어서 더 가보죠. Sanity 는 Structured Content 라는 표현을 자주 사용하는데요, 말 그대로 plain text 보다 구조화된 복잡한 데이터를 다루기 좋은 플랫폼이에요.
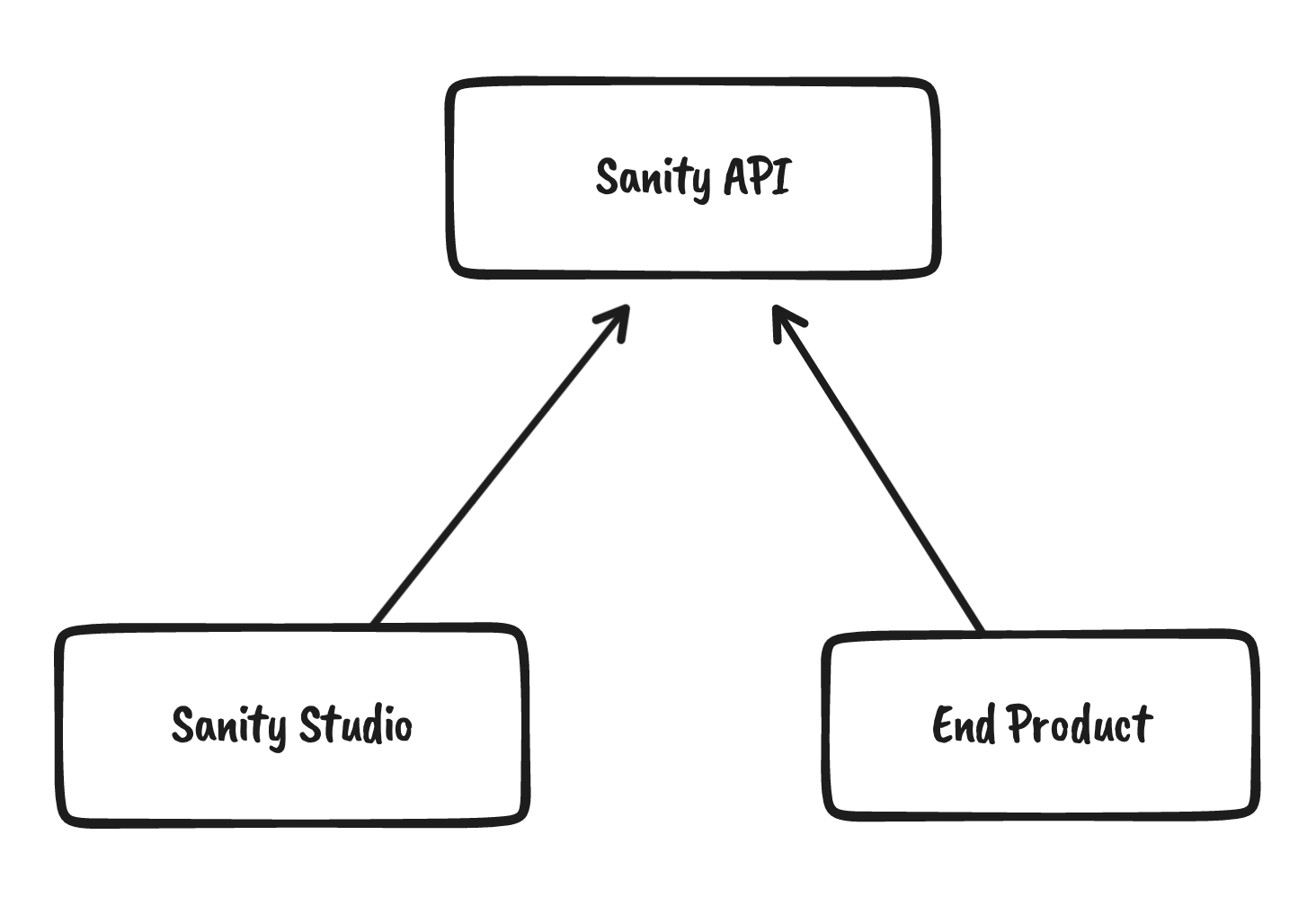
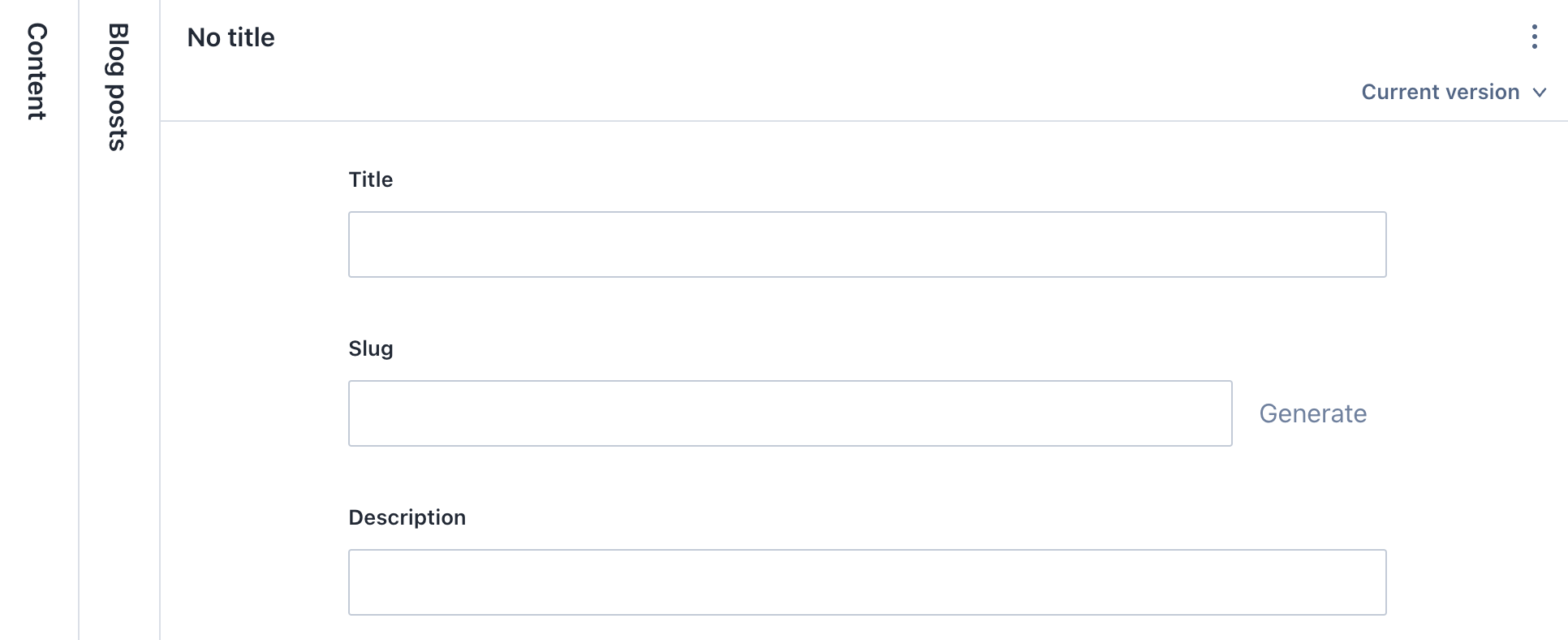
간단히 살펴보면, 새 프로젝트를 만들면 Sanity Studio 라는 프로젝트가 자동으로 생성되는데요. 이건 그냥 쉽게 말해 React 로 쓰인 Admin website 인데요. 이 프로젝트를 여러분 GitHub 에 놓고 배포하신 후에, 그 사이트에 접속해서 컨텐츠를 작성하시게 됩니다. 보통의 CMS 들은 그들의 웹사이트 자체가 어드민 페이지여서 예를 들어, wordpress.com, contentful.com 이런 곳에 로그인해서 글을 작성하고 퍼블리싱하지만, Sanity 같은 경우는 그 어드민 페이지 자체도 유저에게 통째로 내어주는 형태죠. 그래서 여러분은 여러분의 Sanity Studio 코드 내에서 Schema 도 직접 코드로 작성하게 됩니다. 예를 들어 블로그라면, Post, Author 등의 모델을 JSON 형태로 작성하면, Sanity Studio 가 그걸 알아서 입력 Form 으로 만들어줍니다.
export default {
name: 'post',
type: 'document',
title: 'Blog Post',
fields: [
{
name: 'title',
type: 'string',
title: 'Title',
},
{
name: 'slug',
type: 'slug',
title: 'Slug',
options: {
source: 'title',
maxLength: 96,
isUnique,
},
},
{
name: 'description',
type: 'string',
title: 'Description',
},
...
(더 궁금하시면 이 30초짜리 영상을 보세요)
이렇게 JSON 기반으로 Form 이 생성되지만, 여러분이 원하신다면 아예 직접 작성한 React Component 를 제공하심으로써 완전 Custom 한 Form 도 만들 수 있습니다. Sanity Studio 의 코드를 통째로 유저에게 내어줌으로써 유저가 궁극의 Customization 을 할 수 있도록 가능성을 활짝 연 셈이죠. 복잡한 구조의 데이터를 다루는 Form 을 만들 거라면 이보다 좋은 방식은 없지 않나 싶어요.
자, 그러면 Sanity Studio 는 살펴봤고, 그럼 저장된 데이터는 어떻게 가져다 쓰죠? Sanity 가 제공하는 API 를 통해 받아다 사용하면 됩니다. 만드시는 웹사이트가 어떤 Tech stack 을 가지고 있던 상관없이 API 가 내려주는 JSON 을 잘 렌더링 하면 되겠죠. Gatsby 를 쓰신다면 빌드 타임에 정적으로 저 데이터를 받아다 페이지들을 렌더링 하시면 되고, Next.js 를 쓰신다면 요청이 들어올 때마다 Sanity API 를 호출해서 데이터를 받아다 렌더링 하시면 되겠죠.
이런 Headless CMS 방식이 기존의 전통적인 CMS 에 유리한 점은, 주어진 데이터를 기반으로 렌더링을 마음대로 할 수 있다는 점이죠. 한 요리 블로그의 예를 보실까요. 한식에 대한 이야기를 담는 블로그인데, 한국어와 영어 두 버전으로 제공한다고 하시죠.
고추장 30g 을 넣으세요.
라는 문장을 보시면 어떤가요? 별다른 설명이 필요 없죠? 하지만 외국인을 대상으로
Put 30g of Gochujang.
이라고 쓰는 순간, 저 Gochujang 이 뭔지 설명을 해줘야만 할 것 같은 기분이 드는데요. 그렇게 하면 되겠죠? 데이터는 이미 우리 손에 있으니까, 대락 아래와 같은 코드가 가능하지 않을까요.
function Ingredient({ ingredient, lang }) {
if (lang === 'ko') {
return <span>{ ingredient.title }</span>
} else {
return <a href={ingredient.wikiLink}>{ ingredient.title }</a>
}
}심지어 30g 은 미국에서 접속하는 경우 1.05 oz 라고 렌더링 해 줄 수도 있겠네요. 좀 더 궁금하시면 이 트윗을 보셔도 좋을 것 같아요:
혹시 여러분이 지금 구상 중이신 사이드 프로젝트에 Sanity 를 적용시킬 수 있을까요? 한번 떠오르는 대로 답변 주세요. 같이 얘기 나눠봐요.
Supabase
제가 열심히 자료를 모으고 모아서 원기옥 같은 큰 에피소드로 찾아뵈려던 주제가 Supabase 인데요. 그보단 그냥 한번 적당한 길이로 소개해드리고, 추가적인 내용은 천천히 다루면 어떨까 싶어서 오늘 이렇게 들고 나왔어요. Supabase 의 캐치 프레이즈는 The Open Source Firebase Alternative.

제가 Firebase 를 제대로 사용해 본 경험이 없어서 1:1 비교는 어렵지만, 제가 알기로 Firebase 는 NoSQL 데이터베이스를 지원하지만, Supabase 는 PostgreSQL 을 기반으로 합니다.
Supabase 제공하는 기능 및 서비스는 정말 방대한데요. 우선 아래와 같은 심플한 로그인 기능을 제공합니다.
const { user, error } = await supabase.auth.signIn({
email: 'example@email.com',
password: 'example-password',
})그리고 아래와 같이 데이터를 가져올 수 있고요.
const { data, error } = await supabase
.from("posts")
.select("*")
.eq("user_id", userId)
.limit(10);보시면 아시겠지만 굉장히 단순한 코드로 로그인 처리를 할 수 있도록 JavaScript 라이브러리가 제공되고, SQL 에 익숙하신 분들은 위의 데이터 가져오는 예제도 눈에 잘 읽힐 거예요. 또 다른 기능인 Realtime Subscription 은 데이터를 한번 받아 오고 끝나는 게 아니라, 받아 온 이후에 데이터베이스에 변경이 생기면 내가 제공한 callback function 을 통해서 변경된 데이터를 실시간으로 계속 받아 올 수 있는 기능인데요. 이걸 통해서 화면에 데이터를 실시간으로 계속 유지할 수 있게 됩니다.
const mySubscription = supabase
.from('*')
.on('*', payload => {
console.log('Change received!', payload)
})
.subscribe()로그인을 구현하는 상황이면 일반적으로 Access Control 도 구현하기 마련이죠. 예를 들어, 로그인된 유저가 자신의 데이터만 수정, 삭제할 수 있고 남의 것은 읽기만 가능하게끔이요. 가장 쉽게 떠올릴 수 있는 구현 방식은, 프론트엔드에서 백엔드로 요청을 하면, 백엔드는 데이터베이스 전체에 접근을 할 수 있지만 백엔드에 구현해 놓은 Access Control 로직이 해당 유저의 권한에 따라 적절한 쿼리를 하도록 일종의 가드 역할을 해주는 식이죠. 이걸 직접 구현하려고 하면 상당히 손이 가는 곳이 많아요. 하지만 Supabase에서는 이걸 거의 신경 쓰지 않아도 되는 수준으로 도와줍니다(어떻게? 는 지금은 생략할게요).
다른 Database-as-a-service 에 비교해서 Supabase의 가장 큰 장점이라면 Vendor Lock-in이 없다는 겁니다. 무슨 말인고 하면, 자체적인 기술로 특정 기능을 제공해 주거나 아니면 데이터 내보내기를 어렵게 해 놓는 등의 이유로 한번 발을 들이면 묶여버리는 일이 흔한데요. Supabase는 그저 PostgreSQL을 굉장히 잘 활용하는 Wrapper 라는 생각에 듭니다. 그래서 Supabase를 자꾸자꾸 사용하다 보면 ‘이런 기능이 PostgreSQL에 있었어? 이런 PostgreSQL plugin 이 있었어?’ 하는 생각이 들면서, 조금씩 PostgreSQL 실력이 늘게 되더라고요. 게다가 Supabase는 이 데이터베이스에 직접 연결 할 수 있도록 connection string 도 제공이 되기까지 합니다. 꽁꽁 숨겨 놓지 않고 오히려 정 반대로 아예 열어놓습니다. 그래서 원한다면 직접 데이터베이스에 어떤 오퍼레이션을 할 수도 있고 혹은 데이터베이스를 통째로 dump 뜰 수도 있습니다.
그밖에도 데이터베이스에 추가 혹은 변경이 있을 때마다 serverless function을 실행하도록 하는 기능까지도 있고요. AWS S3 같은 파일 스토리지도 제공합니다.
많은 분들이 이런 류의 서비스들을 꺼리는 경우가 있습니다. 가장 큰 이유는 제가 자주 언급한 Vendor Lock-in, 그리고 자유도가 낮다는 점이 아닐까 싶어요. 그리고 그 서비스 만의 특별한 기술 혹은 API를 익히는 Learning Curve가 큰 탓도 있을 거고요. 예를 들어 제가 예전에 사용해 보려고 했던 한 Database-as-a-service as가 있었는데요. Fauna라고 꽤 유명한 서비스이긴 합니다. 그때 한 시간 정도 써보다가 그 정도론 제가 원하는 만큼 진도를 빼지 못했어요. 쿼리도 자체적으로 만든 SQL문법이 아니었고 Access Control 도 기존에 널리 알려진 Role-Based Access Control(RBAC)를 확장한 Attribute-Based Access Control이란 개념을 사용하는데 일단 제가 가진 한 시간이라는 제약, 새로운 개념, 복잡한 문서 등등 여러 요인으로 결국엔 진도를 빼지 못하고 포기하고 넘어갔던 기억이 있어요. 만약 해냈다 쳐도, 나중에 데이터베이스를 교체하고 싶어지면 백엔드를 상당 부분 다 다시 짜야하는 거예요. 게다가 그 서비스가 가격을 말도 안 되게 올려 버리더라도 속수무책으로 낼 수밖에 없는 것이고요. 그런 면에서 Supabase는 꽤 합리적인 것 같아요. 기존에 이미 존재하는 PostgreSQL 을 가져다가 여러 가지 좋은 플러그인을 디폴트로 잘 설치해 놓고 그걸 잘 사용할 수 있게끔 깔끔한 API로 감싸 놓은 게 참 매력적이라고 생각해요. 그리고 그 프로젝트에 굉장히 많은 부분이 오픈소스화 되어 있고 그걸 표방하는 회사답게 Vendor Lock-in 같은 문제들도 현명하게 잘 피하고 있고요.
그러면 다음으로 나올 질문은 ‘Scailability’인데요. 제가 이 에피소드를 작성하고 있는데 우연히도 며칠 전에 Supabase에서 Enterprise Plan을 발표하면서 이제 그 부분도 해결이 될 것 같네요.
그럼 어떤 사람이 Supabase를 써야 되고 어떤 사람이 쓰지 말아야 할까요? 쓰지 말아야 할 경우를 보자면 NoSQL을 사용하고 있고 PostgreSQL을 절대 사용하고 싶지 않은 경우에는 당연히 Supabase를 쓸 수 없겠죠. 혹은 데이터베이스 자체가 필요하지 않은 서비스 거나, Headless CMS 가 더 적합한 경우면 그에 맞는 걸 고르면 되겠습니다. 하지만 Supabase가 어마어마한 기능들은 이미 웬만한 서비스를 만들기에 부족함이 없고 2021 년 가을에 30M USD 의 시리즈 A 투자를 통해, 팀의 규모가 커져 가고, 또 그만큼 계속해서 대단한 기능들을 빠르게 업데이트하고 있는 추세예요. 그래서 적어도 앞으로 몇 년 간 Supabase는 점점 더 멋지게 성장할 서비스라고 생각합니다. 그래서 저는 앞으로 한동안 Supabase를 제 대부분의 사이드 프로젝트의 백엔드로 사용할 생각이에요. 그리고 실제로 지금 제가 만들고 있는 Quill 이란 프로젝트의 백엔드는 이미 Supabase로 굴러가고 있습니다. 
Supabase에 대한 이야기는 여기까지 하고요. 더 궁금하신 점 있으시면 답변 주시면 제가 조사해보고 아는 선에서 답변드릴게요. 사소한 질문도 좋고요.
Quirrel
끝으로 Quirrel 이란 서비스에 대한 소식을 전해드리고 마칠게요. 정확한 히스토리는 알 수 없지만 Quirrel 은 2020년 경에 나온 서비스인데요. Simon Knott이란 한 개발자가 만들었어요. ‘Next.js에 쉽게 Job Queue를 구현할 수 없을까?’ 하는 생각에서 시작되었다고 해요.
// Define your queue ...
export default Queue(
"queues/someBackgroundTask",
async (job) => {
// do your thing
}
)
// ... and use it!
await queue.enqueue({ ... }, {
delay: "1d",
repeat: {
every: "1h",
times: 2
}
})
// That's it! 🥳웹사이트에 있는 위 예제 코드처럼 정말 간단하게 백그라운드에서 길게 작동하는 Job 을 처리할 수 있는 서비스이죠. 어떤 분은 ‘그거 Sidekiq이랑 뭐가 달라?’ 라고 하실 수 있어요. 크게 다르지 않아요. 다만, 같은 문제를 조금 다른 관점에서 조금 다른 기술로 조금 다른 유저를 향해 내놓았고, 그게 매력적으로 다가온 것 같아요. 저는 아직까지 써볼 일이 없었지만 Sidekiq 을 쓰며 좋지 못한 기억들이 많았어서, 이 서비스는 계속 눈여겨보긴 했거든요. 그런데 결국, 지난 2월 Netlify 에 인수되었습니다. 사이드 프로젝트를 만들어서 인수됨으로써 그 회사의 직원이 된다, 꽤 재밌는 루트죠. 하던 프로젝트를 계속 자금 걱정 없이 진행하면서 좋은 회사에서 그 프로젝트의 오너십은 계속 유지한 채 좋은 동료들과 일할 기회가 생기는 것 같아요.
다들 이번 에피소드 어떻게 읽으셨을까요. 언제나 여러분의 메일 기다리고 늘 즐거운 마음으로 답메일 드리고 있으니, 알려주세요!
4월 중순에 갑자기 눈이 오는 바람에 파종한 화분들 십여 개를 베란다에서 거실 안으로 옮겨 놓은 위기의 초보 농부 이은재 드림.